所有权(Ownership) —— 是 Rust 语言最独一无二的特性,它使得 Rust 不需要垃圾回收器来确保内存安全。所以,理解 Rust中的所有权是如何工作的,至关重要。
所有权是什么 ?
所有权是 Rust 语言的核心特色,它和这门语言的其他部分有很深的牵连。
所有程序在运行时,都有管理使用计算机内存的方式,通常有两种方式:
- 使用一个垃圾回收器持续不断的寻找那些不再使用的内存,例如 Java 语言。
- 程序员必须手动分配和释放内存,例如, C++ 语言。
然而 Rust 是一朵奇葩,它使用了第三种方式
- 通过带有一系列规则的一个所有权系统来管理内存,编译器会在编译期间检测代码是否遵循了这些规则。
所有权这个概念对大多数程序员来说都是一个新概念,但是对所有权系统的规则掌握的越熟练,就越会写出高效而安全的代码。
关于栈和堆
- 在很多编程语言中,并不需要经常思考关于栈(Stack)和堆(Heap)的问题,但是对于像 Rust 这样的系统编程语言,一个值是在栈上还是堆上对于语言的行为以及为什么我们会作出某些决定有很大影响。
- 栈和堆都是我们的代码在运行过程中可以使用的内存部分,但是他们组织数据的方式不同。
- 栈的数据结构类似于一垒盘子,存数据时只能在最顶部添加,移除数据时也只能从最顶部移除(Last In First Out),而且存取的数据必须是已知固定大小的 —— 已知是指在编译期间已知。
- 堆的数据结构不像栈那样紧凑,比较松散,用于存储在编译期间还不知道大小或者大小有可能会改变的数据。当我们要将数据存储到堆上时,系统会在堆上找一个还未占用且足够大的空间,然后将其标记为已经占用,然后返回给我们一个指向那块空间的指针,这个过程被称为 —— 分配(Allocating), 因为指针的大小是固定的,所以可以将指针存储在栈上。
- 由于栈上的数据紧凑且大小固定,而访问堆上的数据需要根据指针的指向寻找数据 —— 需要频繁在相距很远的数据之间跳转,所以访问堆上数据的速度比访问栈上数据的速度更慢。
- 当我们调用一个函数时,传入函数的值(包括指向堆上数据的指针)都会被推入(Push)栈中,当函数结束,这些值会被弹出(Pop off)栈。
- 持续跟踪哪些代码正在使用堆上的哪些数据,以最小化堆上的重复数据并清理不使用的数据,以防止耗尽空间正是所有权要解决的问题。
所有权规则
- Rust 中的每个值都有一个变量 —— 该变量的所有者(owner)
- 在一个时间段内只能有一个所有者
- 当所有者超出作用域范围,值会被删除
变量的作用域
一个元素的 作用域 是一个程序里的一个范围,在这个范围内该元素是有效的。
fn main() { // 在这里 s 是无效的,因为它还没有被声明
let s = "hello"; // s 从这里开始生效
// 接下来可以开始使用 s 做些事情
}//s 的作用域从这里结束,s不再有效
从上边的代码,我们可以总结出两点:
- 当 s 出现在作用域中,它开始有效
- 一直保持有效,直到该作用域结束
String 类型
为了说明所有权的规则,我们需要一个复杂一点类型,因为我们之前在文章 常见编程概念在Rust中是如何被使用的 中提到的数据类型都是在编译期间就大小已知且固定的——使用它们作为变量类型的数据会被推入栈中;当变量作用域结束时会被从栈中弹出;当在不同作用域需要使用相同值时可以被很快复制创建一块完全独立的空间;所以太过简单无法使用它们来充分说明Rust是如何处理堆上的数据的——怎么样以及什么时候该清理。
所以我们接下来使用 String 类型来详细说明这类复杂类型是如何在堆上和栈上存储的,当不再需要的时候 Rust 是如何知道并且清理它们的,以及在这一些列过程中Rust有些什么所有权规则需要我们了解。
字面量(Literal)
在上边我们有用到这样一行代码:
let s = "hello";
如果你想当然的认为上边的字符串是一个String类型,那就错了!!! ——String 类型是包含在Rust标准库中的一个类型,通常需要通过调用String类型中的方法来创建,而上边的"hello"是完全不同的另一个概念——是被叫做字符串字面量(string literal) —— 在计算机编程中 字面量(Literal) 代表源代码中的一个固定值: 比如 let i = 1; 中的 1 就是一个整数字面量。
字面量是固定值所以不可修改,但是 String 类型可以。
let mut s = String::from("你好");
s.push_str(",小明");
println!("s: {}", s);
内存和分配
是什么原因导致字面量无法被修改,而String类型却可以呢。
主要原因在于他俩处理内存的方式不同:
- 由于字面量是固定值——无法修改,被硬编码到源代码中,最终被编译到可执行程序中,当程序运行时会被加载到内存中。所以在编译时就已经确定占用的内存空间——无法存储大小不确定的内容。
- 而标准库中提供的 String 类型则不同 —— 它是将数据存储到堆上,所以可以存储在编译时还无法确定大小的内容,而且可以被修改。
对于在堆上存储的数据类型:
- 在运行时向内存分配器申请空间
- 当超出作用域范围时,要将申请到的分配空间还回去
对于申请内存空间,String类型可以使用 from 方法 ,申请内存空间每个编程语言的处理方式一样
let mut s = String::from("你好");
但是对于回收内存空间,每个编程语言的实现方式有所不同,比较主流的有两种方式
- 通过垃圾回收器GC(garbage collector),持续跟踪不再被需要的内存并回收, 像Java使用这种方式。这种方式的优缺点是:
- 优点是程序员不需要关注内存回收的问题,不像rust有权限规则的限制
- 缺点是由于使用了GC导致更复杂的运行时环境,然后运行性能较慢 - 程序员手动回收,需要程序员去判断哪个变量不再被需要,然后手动释放内存,像 C/C++ 使用这种方式,这种方式的优缺点是:
- 优点是运行时环境简单,所以运行性能好
- 缺点是需要程序员手动释放变量的内存空间,而且每个空间的申请和释放必须是一对一匹配的,如果释放的太早会造成变量过早无效,如果忘记释放又会造成内存泄漏,如果重复释放也会造成程序崩溃,所以程序员编写代码繁琐而且容易出错。
而 Rust 没有采用上面的任何一种,而是独辟蹊径创造了自己回收内存的方式:
- 一旦变量超出作用域的范围,其内存空间会被自动回收
{
let s = String::from("hello"); // s 变量从现在开始生效
// 接下来可以操作变量 s
}//该作用域结束,s变量不再有效
上面的代码,在大括号这个作用域里,首先通过 String::from 向内存管理器申请了一段内存空间,然后变量 s 开始有效,直到遇到大括号,当遇到大括号时 Rust 会自动调用 String 类型中的一个方法 drop , String类型的实现者可以在这个方法里释放刚才申请到的内存。
到目前为止看起来很简单,但是当有多个变量共享数据时,事情就会变得复杂起来,我们继续看 -->
通过(移动)Move实现变量和数据的交互
在 Rust 中当多个变量与相同数据交互时,根据数据类型的不同,他们操作内存的方式是非常不同的。
标量数据类型
let mut x = 5;
let y = x;
println!("x: {}, y: {}", x, y);
x = 6;
println!("x: {}, y: {}", x, y);

上边首先将一个整型变量赋给了变量 x, 因为整型变量是大小固定的,所以将变量 x 赋给 y 时,会完全复制x中的值然后赋给 y。因为整型变量是大小已知且固定的,所以会被推入栈中。从输出中可以看到因为y的值是通过复制了一个完全独立的x的值,所以一旦赋值完成,x和y没有内在联系,y不会因为x的改变而改变。
标量数据类型都是在栈中存储的,所以比较简单,对于在堆上存储的数据类型就会复杂很多 ——>
复杂类型
let x = String::from("hello");
let y = x;
从源代码层面看,只是将上边的整数类型变成了 String 类型,但是在内存上的表现却已经大大不同了:因为 String 类型存储的内容占用空间大小不固定,而且可以被修改,所以只能存储在堆上。
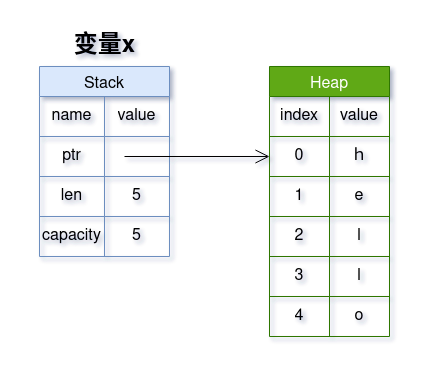
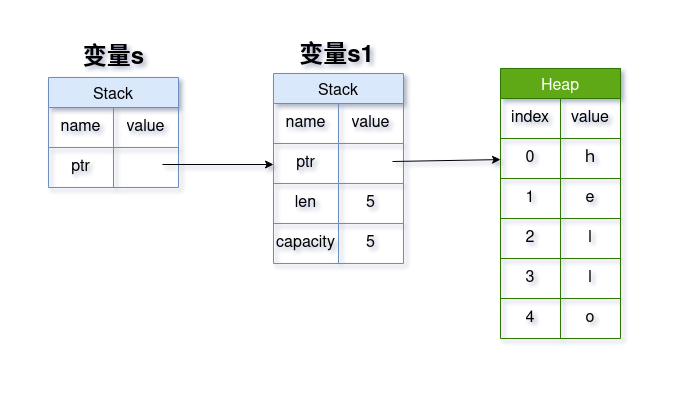
上图是变量 x 在内存中的结构图,所有数据分别存储在内存中的两个地方
- 栈(Stack)中,存放元数据:
- ptr: 指针,指向存放字符串的堆内存地址
- len: 字符串占用的字节长度
- capacity: 变量x向内存分配器申请到的堆内存大小,单位也是字节 - 堆(Heap)中,存放字符串
我们上边分析堆栈的区别时讲过,在栈上只能存储固定大小的数据,而且访问栈上的数据速度快。
所以对于复杂类型的数据,将堆内存的地址(大小固定)和内存大小,存储内容大小这些占用内存较小而且大小固定的数据存储在栈上,将占用空间较大而且大小不可知的内容存放到堆上。
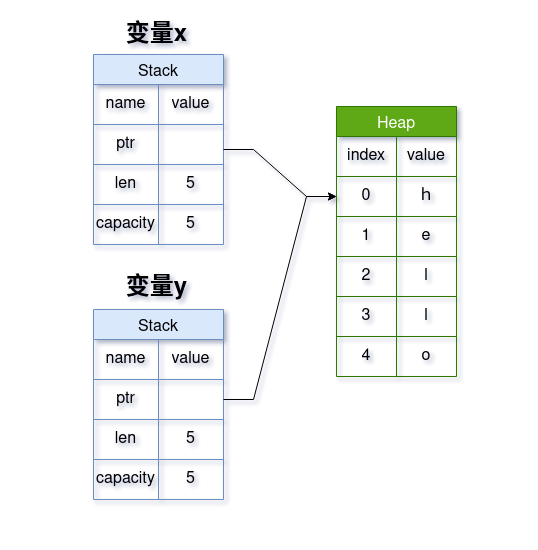
当我们将字符串 x 赋值给 y 的时候,和上边将整型 x 赋值给 y 是一样的——也是只会复制在栈上的这部分数据:
而不是大家以为的:
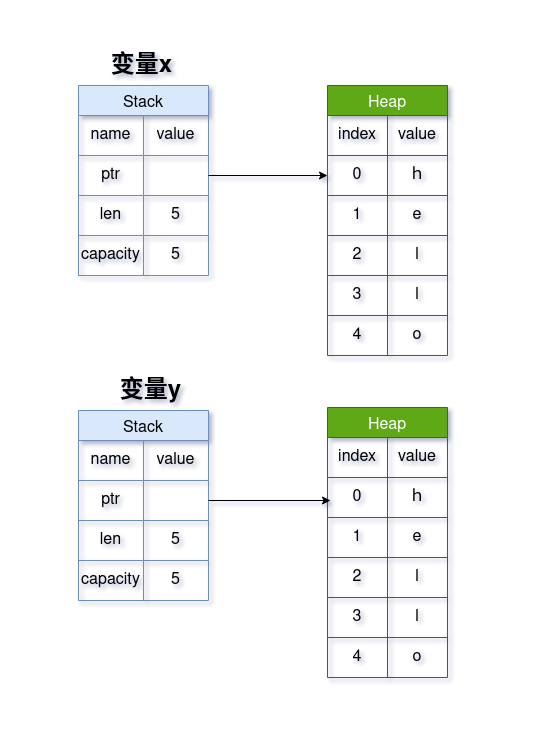
因为堆上的内容占用空间较大,复制所需要的时间和空间成本都太高了。
因为现在变量 x 和 y 中的指针都指向了相同的一块堆地址,所以当它两超出作用域范围的时候,Rust 应该都会调用 String 的 drop 方法来释放内存,但是这会造成重复释放内存的问题,那么 Rust 是怎么解决这个问题的呢:
当变量 x 赋给 y 后,Rust会撤销变量 x 的有效性,变量 x 无法再被使用
所以也就只剩下变量 y 对相同的内容拥有所有权,所以只有当变量 y 超出作用域范围时才会释放内存,因为变量 x 对堆内容不再拥有所有权,所以当它超出作用域范围时,rust不会尝试释放内存。
变量 x 赋予 y 的过程,相当于是将数据内容的所有权转交的过程,也叫移动(Move)。
let x = String::from("hello");
let y = x;
println!("x: {}", x);
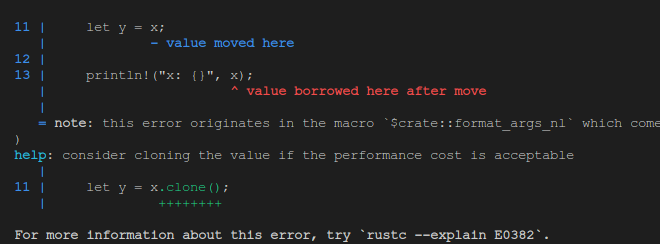
当所有权交出去后,变量 x 变得无效,所以无法再被使用。
通过克隆(Clone)实现变量与数据的交互
复杂类型
我们已经知道,默认情况下将一个复杂数据类型的变量赋值给一个新变量时只会复制栈上的部分,那么如果我们确实想要同时复制堆上的内容有方法吗?
在Rust中在赋值时通过明确调用clone方法可以实现也复制堆上内容的目的。
let x = String::from("hello");
let y = x.clone();
println!("x: {}, y: {}", x, y);

可以看到通过调用clone方法赋值给变量 y 后,变量依然有效:因为通过调用 clone 方法赋值,栈上和堆上的数据都被复制了,这样就和标量类型一样——两个变量内存之间是完全独立的,所以当他们超出作用域范围的时候,当Rust调用 String 的 drop方法时不会造成重复释放内存的问题。
标量数据类型
正如我们上边通过Move实现变量和数据交互中讲到,因为标量类型的数据大小固定,并且在编译期间就已知,所以他们只被存放在栈中——复制容易,访问快速。所以将它们赋予一个新的变量时,复制栈上的内容就已经是它们的所有内容(在堆上不存放数据),所以就不存在需要通过调用clone方法复制堆上内容的情况。
Copy trait
Rust中的 trait类似于 java 中的接口 interface 、抽象abstract方法或default方法等,实现某个trait的类型需要实现这个 trait中指定的一些方法,所以实现这个trait的类型会有一些共通的特性。
上边我们有讲到那些内容存放在栈上的数据类型都有一个特性 —— 变量和数据的交互不使用移动(Move)的方式,而是直接复制栈上的内容,赋予新变量后,旧变量依然有效。这个共同的特性就是因为这些类型都实现了Copy trait。
如果我们希望自己的类型也拥有这个特性,需要具备条件:
- 这个类型或者该类型包含的子元素的类型没有实现
Droptrait 。
这个很合理,因为Droptrait是用于释放堆上内存的,如果实现了drop说明它在堆上存放数据了。
Rust中实现Copytrait的数据类型有:
- 所有的整数类型
- 所有的布尔类型
- 所有的浮点类型
- 所有的字符类型
- 所有子元素类型都实现了
Copytrait的tuple
所有权和函数
传递函数参数和作用域
上面我们详细了解了针对不同的数据类型变量x,当把它的值赋予变量 y 的时候,在内存中发生了什么。
当我们调用函数,传递参数值的时候和向变量赋值是一样的,只是赋予的变量是函数中的参数而已,参数也是函数中的变量。
所以如果传入的值是实现了Copy trait的类型也会发生复制;如果传入的是复杂类型,例如String, 权限也会转移,并且旧变量不可以再被使用。
fn main() { // 在这里 s,x 是无效的,因为它们还没有被声明
let s = String::from("hello"); // 复杂类型 String 变量 s 开始生效,进入作用域
takes_ownership(s); // 变量 s 赋予函数参数变量 some_string, 变量 s 失效
// 变量 s 失效,不可以再被使用
// println!("调用take_ownership函数后的s: {}", s); //发生编译错误
let x = 5; // 整型变量 x 开始生效,进入作用域
makes_copy(x); // 变量 x 赋予函数参数变量 some_integer, 因为整型实现了 Copy trait, 所以直接复制
// 变量 x 依然有效,可以继续使用
println!("调用make_copy函数后的x: {}", x);
} // 变量 x、 s 超出作用域,变量 x 被从栈中弹出,变量 s 的所有权已经被转给函数变量 some_string 所以不需要释放s的内存
fn takes_ownership(some_string: String) {// 函数参数变量 some_string开始生效,进入作用域
println!("some_string: {}", some_string);
} // 函数参数变量 some_string 超出作用域,Rust调用 drop 方法释放它的内存
fn makes_copy(some_integer: i32) { // 函数参数变量 some_integer 开始生效,进入作用域
println!("some_integer: {}", some_integer);
} // 函数参数变量 some_integer 超出作用域,被弹出栈
返回值和作用域
上面了解了传递函数参数与向变量赋值没什么不同,其实函数的返回值赋予一个变量也是同理。
fn main() { // 在这里 s1,s2,s3 是无效的,因为它们还没有被声明
let s1 = gives_ownership(); // gives_ownership 将其返回值赋予了变量 s1, 因为返回类型是 String, 所以将权限Move到了s1
// s1开始生效,进入作用域
let s2 = String::from("hello"); // 复杂类型 String 变量 s2 开始生效,进入作用域
let s3 = takes_and_gives_back(s2); // 因为s2是String类型,将所有权Move到了函数参数变量a_string,
// 变量s2失效,无法再被使用,函数takes_and_gives_back将返回值所有权
//赋予了变量 s3, 变量s3开始生效,进入作用域
} // 变量 s3,s2,s1 超出作用域,由于s2已经失效,Rust调用 drop 方法释放 s1,s3的内存
fn gives_ownership() -> String {
let some_string = String::from("yours"); // 变量 some_string生效,进入作用域
some_string // 变量 some_string 将所有权返回给调用函数,some_string变量失效
} // some_string 变量无效,无需调用drop方法释放内存
fn takes_and_gives_back(a_string: String) -> String { // 变量 a_string 生效并获得所有权,进入作用域
a_string // 变量 a_string 将所有权返回给调用函数,a_string 失效
}// a_string 变量已经无效,无需调用 drop 方法释放内存
所以向函数传递参数和函数的返回值赋予一个变量,本质上也都是将值赋予一个变量。区别只是,向函数传递参数是将一个值从当前作用域传递到被调用函数的作用域,而返回值是将函数作用域中的值传递到当前作用域——它们都遵循上边讲到的变量和数据交互的规则。
所以,当我们将当前变量的值传入到一个函数的作用域中时,当前变量就失效了,无法继续使用,如果在当前作用域还希望继续使用那个值,还必须要向上面代码中的变量 s2 那样返回来。
一个函数如果既想要返回传入的值,又要返回其他值,可以通过tuple这个复合类型来装载:
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("'{}' 的长度是: {}", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len();
(s, length)
}

引用和借用(Borrowing)
上边的代码中,我们调用 calculate_length 方法计算字符串长度的时候,如果在接下里我们还需要使用那个字符串,我们不得不在 calculate_length 的返回值中返回字符串的权限。
但是对于绝大多数的函数调用,我们都希望将值传入函数后可以继续使用它们,而不是再也无法使用这些值了。就像我们在生活中,如果朋友向我们借用一些东西,我们都是本着助人为乐的态度尽可能帮助别人,只要按时归还就好,但是如果借出去的东西再也要不回来了,那就非常让人沮丧了。
像如此普遍的情况,难道每次我们调用函数都要把权限传进去,再传出来吗 ? 如果真的必须这样的话,那Rust 这门语言也就像大部分臃肿腐败的政府一样办事流程繁杂而低效了,没有高效廉洁可言,也就不会有这么多人喜欢了。
引用的借用
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("'{}'的长度是: {}", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
和上边的代码版本相比:
- 调用函数calculate_length函数时传入的是
&s1而不是s1 - calculate_length 函数的参数类型是
&String而不是String - calculate_length 函数的返回类型是
usize而不是(String, usize)
在变量名前加 & 叫做该变量的引用, 引用类似于指针的概念:它们都存有一个地址,可以跟踪这个地址找到实际存储的内容;和指针不同的是,在引用的整个生命周期总是指向有效的值,而指针有可能指向 一个空值。
那么引用和变量有什么区别呢?从上边对 calculate_length 函数调用,我们看到把引用传入后,没有再返回,可以大体推断出:
引用不拥有对数据的所有权,那么当引用的生命周期结束的时候也就不会有释放内存的说法
就像我们在生活中,当朋友要借用我们的车,我们可以口头授意他(她)可以暂时使用(&)我们的爱车,但是没有必要将车的所有权过户(Move所有权)到朋友的名下,所以朋友借到车后可以使用(读取),但是没有权利去处置车,比如卖给别人(Move)或者销毁掉(drop)。
和我们借给朋友车一样,当我们创建一个变量的引用也被叫做借用(borrowing)—— 借用数据。
既然可以通过引用借用到数据,那么是否可以通过引用修改数据呢 ?
引用的修改
fn main() {
let s1 = String::from("hello");
change(&s1);
}
fn change(s: &String) {
s.push_str(", world");
}

编译错误告诉我们:s 是一个 &引用,所以它指向的数据不能被以可修改的方式借用。
这个暗含的意思就是可以以可修改的方式借用喽 —— 是的
Rust中的引用和变量一样,默认是以不可修改的方式借用,如果要以可修改的方式借用也是在变量前加
mut关键字
fn main() {
let mut s1 = String::from("hello");
change(&mut s1);
println!("修改后的s1: {}", s1);
}
fn change(s: &mut String) {
s.push_str(", world");
}

和上边相比,我们只是把函数的参数从引用&变为了可修改引用&mut 。
还有没有其他区别 ???有—— 我们把变量 s1 也从默认不可修改变量变为了可修改变量mut s1 。
why ? 其实这个也很好理解,如果变量是不可修改变量,那就意味这它的数据内容是不可修改的,毕竟变量 s1才是数据的所有者,如果所有者都无法修改,那么我们这个借用者 &mut s1 又有什么资格去修改呢,所以借用者&mut s1可以修改的前提是 —— 所有者指定其数据内容是可以被修改的。
就像我们借给朋友的车,我们可以借给他(她)只让使用(&),也可以借给他们后允许他们换轮胎(&mut)比如他们要去越野,他们可以换轮胎的前提是这个车的轮胎是可以更换的——我们自己(所有者)可以更换(mut s1),如果我们自己都无法更换,那说明这台车的轮胎本身就是不可更换的 (s1);但是即使我们允许他们更换轮胎,这个车的所有权依然属于我们,他们没有处置这台车的权利,比如过户给别人(Move)或者销毁(Drop)。
但是当涉及到可修改引用的时候,有一条非常非常重要的规则需要遵守:
在一段时间内,如果对一个变量已经有一个可修改引用,对该变量不可以再有其他引用(&和&mut)
上边这句话非常简单,简单在于第一个逗号后边的内容非常容易理解,但是只要包含上第一个逗号之前的 在一段时间内 ,整句话就变得非常难以理解。所以要想理解这条规则,重要的是理解这里的 在一段时间内 是什么意思?
既然无法理解第一个逗号之前的内容,我们就先从简单的第一个逗号后边的内容开始剖析:
如果已经有一个可修改引用,可能会存在两种可能:
- 再有可修改引用
- 再有不可修改引用
再有可修改引用
fn main() {
let mut s1 = String::from("hello");
let r1 = &mut s1;
let r2 = &mut s1;
println!("r1: {}, r2: {}", r1, r2);
}
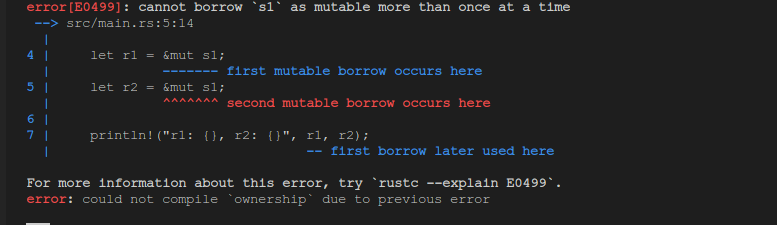
从上边的报错信息截图中看到: let r1 = &mut s1; 和最后一行打印 println!("r1: {}, r2: {}", r1, r2); 的提醒信息是蓝色的,中间let r2 = &mut s1;的提醒信息是红色的,而且最后一行的提醒信息中有 later ,这些提醒信息综合起来似乎在告诉我们,第一行和最后一行代码没有错误,中间的 let r2 = &mut s1; 不应该出现在那个位置,而最后一行打印出现的太迟了。
根据提醒,我们做些调整:
fn main() {
let mut s1 = String::from("hello");
let r1 = &mut s1;
println!("r1: {}", r1);
let r2 = &mut s1;
println!("r2: {}", r2);
}

成功允许!!!
why ? 为什么我们只是将第二个可修改引用的创建放到 println 后边就没问题了呢?
修改前和修改后的代码,变量r1 和 r2都是在同一个作用域里呀!!!
如果我们使用一个新的作用域隔开呢 ?
fn main() {
let mut s1 = String::from("hello");
{
let r1 = &mut s1;
}
let r2 = &mut s1;
println!("r2: {}", r2);
}

也没有问题,这次这个可以理解,因为 r1在一个独立的作用域里,当这个作用域结束的时候,变量 r1 就失效了,所以看来在两个不同的作用域的时候,对于一个变量,是可以存在两个可修改引用的。
那么上边那条规则中的 在一段时间内至少应该是局限在同一个作用域内的,可是在同一个作用于内,为什么同一个变量的两个可修改引用紧挨在一起不可以,但是中间隔一个 println 就可以了呢?
这是否说明 在一段时间内是指比同一个作用域更小的范围呢 ?
这个问题先放在这里,我们继续看第二种情况 ——>
再有不可修改引用
fn main() {
let mut s1 = String::from("hello");
let r2 = &mut s1;
let r3 = &s1;
println!("r2: {}, r3: {}", r2, r3);
}
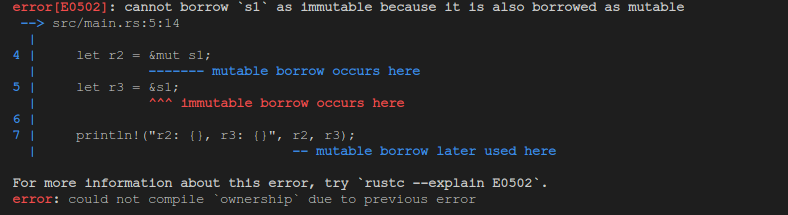
可以看到报错和上边第一个例子 一模一样。
如果也将 r2 的打印放在 r3的赋值前边:
fn main() {
let mut s1 = String::from("hello");
let r2 = &mut s1;
println!("r2: {}", r2);
let r3 = &s1;
println!("r3: {}", r3);
}

运行成功
这是不可修改变量出现在可修改变量后边,如果出现在前边效果是一样的——也是它们中间有一个 println 会成功编译,如果紧挨着会编译报错。
那么这个 println 到底做了什么事情会有这样的影响呢 ?它打印了前一个引用的内容
如果不打印会怎么样呢?
fn main() {
let mut s1 = String::from("hello");
let r2 = &mut s1;
println!("r2: 不打印");
let r3 = &s1;
println!("r3: {}", r3);
}

哇哦,竟然也成功运行了!!!
那如果我们纯粹把中间的打印去掉呢 ?
fn main() {
let mut s1 = String::from("hello");
let r2 = &mut s1;
let r3 = &s1;
println!("r3: {}", r3);
}

我靠,神奇的事情发生了,竟然也成功运行了。那看来一直阻碍成功运行的原因和中间有没有 println 打印也没有必然的关系!!!
那为什么 第一个例子 发生编译错误,而上边这个却成功运行了呢,它两之间唯一的区别就是第一个是这样打印的 println!("r2: {}, r3: {}", r2, r3); 而成功编译的是这样打印的 println!("r3: {}", r3);
所以到这里我们可以得出一个总结: 一直阻碍我们成功运行的原因是, 第一个引用的使用 (println)出现在了引入第二个引用的后边—— 换言之,第二个引用的引入出现在了第一个引用的引入和使用之间。
这意味着,要想编译成功,当在一个作用域内存在一个变量的两个引用的时候,只要其中有一个是可修改引用, 那么 第一个引用的引入和第一个引用的使用之间不应该引入第二个引用。
而一个引用的引入 到它的最后一次被使用这个时间范围被叫做这个引用的生命周期
所以,到这里我们就彻底搞明白了上边的那条规则里边第一个逗号之前的 在一段时间内 就是指引用的 生命周期 。
那么上边的那条规则就可以翻译为:
不可修改引用的生命周期不可以与同一个变量的其他引用(&和&mut)的生命周期发生重叠
对于引用的生命周期的理解,如果看到这里你还是没有清晰的理解,说明我的解释还是不够好,这里有一个详细而深入的解释: https://users.rust-lang.org/t/scope-of-a-variable-with-mutable-and-immutable-references/53807 也许它会更适合你。
而之所以讲到可修改引用的时候会有这条规则,是因为可修改引用有修改数据的能力,所以当有可修改引用和不可修改引用混在一块的时候,会有数据争用 的问题,也叫 数据竞争(Data races)。
但是,不仅可修改引用有修改数据的能力,变量也可以:
fn main() {
let mut s1 = String::from("hello");
let r2 = &mut s1;
s1 = String::from(", World");
println!("r2: {}", r2);
}
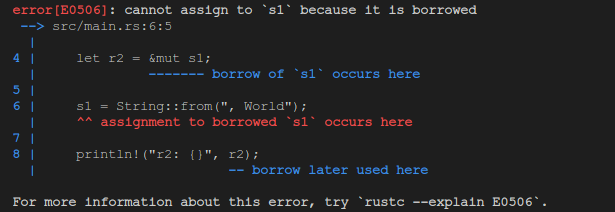
可以看到当在可修改引用的生命周期期间通过其变量修改数据内容也是不被运行的 —— 因为也会有 data races 的问题。
那么如果是在不可修改引用的生命周期期间修改数据内容呢 ?
fn main() {
let mut s1 = String::from("hello");
let r2 = &s1;
s1 = String::from(", World");
println!("r2: {}", r2);
}
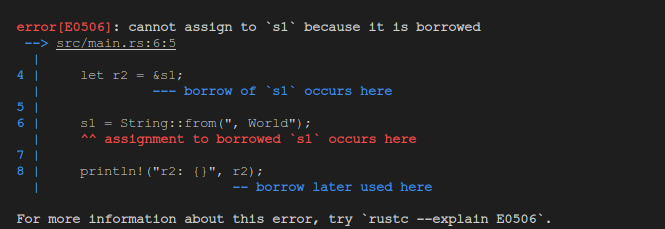
不出所料,也是不被允许的 —— 因为也有数据争用的问题,因为在引用被引入和最后一次被使用的期间数据被修改了,或者有被修改的可能性,这样的多重可能性会导致数据的不可测。
由此可见上边的那条规则的描述的适用范围只包含了可修改引用和不可修改引用的情况,如果再把变量的修改包含进来,应该这样描述:
在可修改引用的生命周期期间,不可以引入对该变量的其他引用(无论是&还是&mut)而且数据内容不可以通过其变量修改;同样的在不可修改引用的生命周期期间,不可以引入可修改引用或通过变量修改数据内容。
我们折腾了这么大半天总结出的这条规则,它的唯一目的是防止出现数据争用(Data races)。
而只有当有可能数据被修改的情况下,才会出现争用的情况,比如出现了可修改引用或通过变量修改数据,所以当它两出现的时候就需要确保它们的存在不会影响到其他人访问数据的确定性。
如果我们把数据内容比作饭店里的菜单,就拿阳春面来说,客人下单时看到菜单上写的是一份阳春面里有两个鸡蛋,那么当他收到的时候就应该也是两个鸡蛋,而不应该是拿到的是一个鸡蛋。如果你要修改菜单,那也应该要先把已经下单的客户都交付了,然后才可以修改菜单,然后新的客户按照新的菜单下单,这样客户拿到只有一颗鸡蛋的阳春面也会感觉合情合理,因为他就是按照一个鸡蛋的新菜单下的订单。然而,如果我们在还没有交付所有有已经下单客户的情况下就修改菜单,就会有客户在下单时是看着两个鸡蛋的菜单下的单,而收到的却是一个鸡蛋的阳春面,这样就会让这些客户感到莫名其妙甚至是愤怒。
而我们上边的那条规则就是为了防止出现像最后让客户莫名其妙甚至愤怒的情境。
这整个过程中,我们把修改菜单这个操作叫做独占性(Exclusive action)操作 —— 因为在修改菜单之前需要确保所有客户已经下的单都交付了,并且在修改菜单期间不接受新的订单,直到修改菜单完成后,客户可以按照新的菜单下单。
而我们上边讨论到的规则中的 可修改引用 和 通过变量修改数据内容 以及变量的Move就是这样的独占性操作。
比照我们上边提到的菜单的例子,我们就可以将上边我们总结的规则做进一步的提炼:
任何
独占性操作(Exclusive action)之前的引用都不应该在该操作之后再被使用
但是到这里,就有一个特例需要理解, 那就是再借用(Reborrowing)
再借用(Reborrowing)
先看两段代码
fn main() {
let mut s1 = String::from("hello");
let r2 = &mut s1;
s1.push_str(", world");
println!("r2: {}", r2);
}
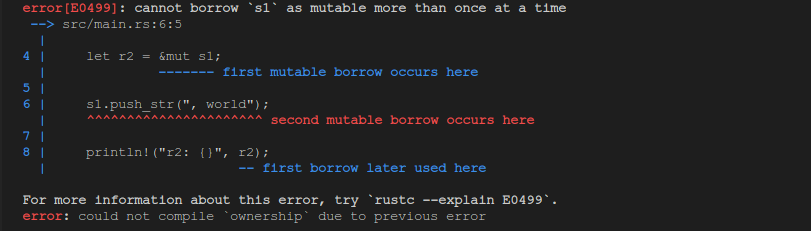
问题一: 为什么这段代码无法编译 ?
fn main() {
let mut s1 = String::from("hello");
let r2 = &mut s1;
r2.push_str(", world");
println!("r2: {}", r2);
}

问题二: 为什么这段代码可以编译 ?
// TODO: 关于再借用的内容先留空,后边再解决…
悬挂引用(Dangling)
在有指针概念的编程语言里经常有悬挂指针(Dangling Pointer)的问题 —— 指针指向的内存地址的内容已经被释放了或者已经被存放了新的内容,但是指针并不知晓。
但是在 Rust 中,编译器在编译期间就会确保所有引用在其整个生命周期中始终都是有效的:
fn main() {
let dangling_reference = dangle();
}
fn dangle() -> &String {
let s1 = String::from("hello"); // 变量 s1 生效,进入作用域范围
&s1 // 返回一个对刚才创建的字符串的引用
} // 变量 s1 超出作用域范围,调用 drop 方法,字符串内存被释放,引用&s1指向了无效的内存
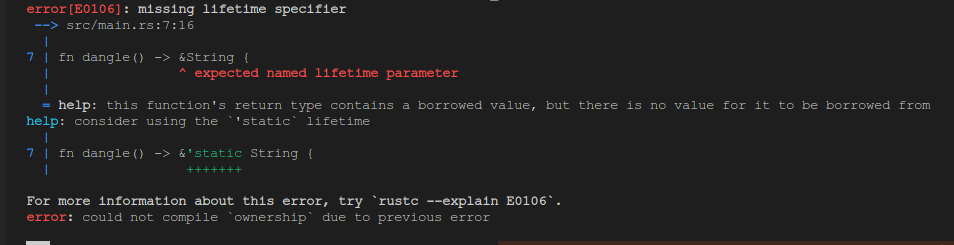
切片类型(Slice)
Rust 中的切片类型也是一种引用,不过它不像我们上边提到的引用直接引用的是变量在内存中的整块数据内容,而是引用其整块内容的一个切片。
大家是否吃过切片面包(Sliced bread)

就是一整块大面包被切成一块块小切片。
如果把这一整块大面包比作变量在内存中存放的数据整体,我们在 引用和借用 中已经讲到的引用就是引用这个整体的,而现在在讲的切片类型就是引用这一整块数据中的一块小切片。
而 Rust 中的
切片类型主要就是引用集合中的子集合,比如字符串,数组等
字符串切片
fn main() {
let s1 = String::from("hello world");
let hello: &str = &s1[0..5]; // 通过指定开始索引和结束索引确定切片的范围
let world = &s1[6..11]; // 切片内容包含开始索引,不包含结束索引
let world1 = &s1[6..s1.len()]; // 索引可以使用变量
println!("hello: {}, world: {}, world1: {}", hello, world, world1);
let hello2 = &s1[..5]; // 如果开始索引从0开始,可以省略
let world2 = &s1[6..]; // 如果结束索引到结尾,可以省略
let whole = &s1[..]; // 如果开始索引从0开始,结束索引到结尾,都可以省略
println!("hello2: {}, world2: {}, whole: {}", hello2, world2, whole);
}

如果你将上边的代码复制到 VScode 中会发现,Rust编译器会自动给这些字符串切片指定为 字符串切片&str 类型,而我们在上边提到的 字符串字面量 也是 &str 类型。
所以在Rust中
字符串字面量就是字符串切片类型, 而切片是一个共享引用,所以字符串字面量不可修改
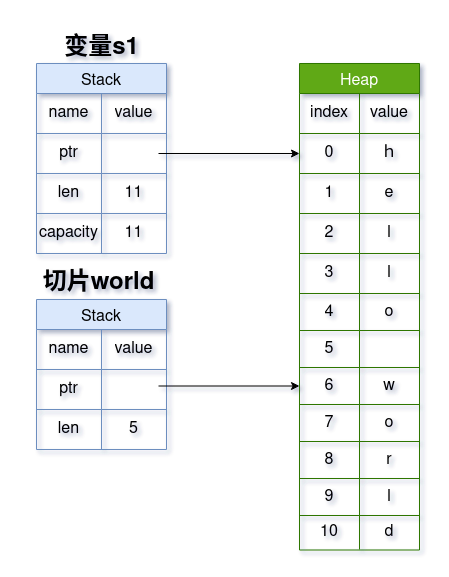
可以看到,切片类型的 ptr 指向的是其开始索引, 然后有一个切片长度 len 。
所以:
切片类型和不可修改引用非常相似,区别只是切片类型的
ptr指向的是切片的开始索引,然后需要len来限定切片的长度;而不可修改引用也叫共享引用(shared reference),其ptr指向的是整块数据的开始索引0,也不需要限定长度,因为默认就是整块数据。
然后数组切片也非常类似 ——>
数组切片
fn main() {
let arr = [1, 2, 3, 4, 5, 6];
let slice1 = &arr[0..5];
let slice2 = &arr[5..6];
println!("slice1:{:?}, slice2: {:?}", slice1, slice2);
let slice11 = &arr[..5];
let slice22 = &arr[5..];
let whole = &arr[..];
println!("slice11: {:?}, slice22: {:?}, whole: {:?}", slice11, slice22, whole);
}

和字符串切片几乎一样,只是数组切片的类型是&[元素类型]。
切片的优势
在上边了解 共享引用(shared reference 的时候我们知道了,共享引用最大的好处是可以在不获取数据所有权的情况下读取到数据。而且我们也已经了解到当有可能发生数据争用(data races)的时候,rust会通过怎样的规则来确保引用读取到的是正确的数据,而且确保引用总是有效的 —— 而这些都是针对整块内容的。
因为切片也是一种共享引用(shared reference),所以这些对于共享引用所拥有的优势及保护,对于切片也适用 —— 而这是针对数据的切片的。
比如,有一个正序排列的 f32 数组,我们希望获取大于其平均值的子集:
如果不使用切片,我们只能这样做
fn main() {
let mut arr = vec![1.3, 4.5, 8.3, 10.5];
let greater_index = greater_than_avg(&arr); // 计算大于平均值的元素索引值
arr.clear(); // 清空数组,危险!!!
println!("{}", greater_index);
}
fn greater_than_avg(arr: &[f32]) -> usize {
let sum: f32 = arr.iter().sum(); // 计算所有元素的总和
let avg = sum / arr.len() as f32; // 计算平均值
for (index, item) in arr.iter().enumerate() {
if item > &avg{ // 如果大于平均值
return index; // 返回索引值
}
}
arr.len() // 只有一个元素,或者为空的情况
}

这样的操作对于有编程经验的朋友应该是非常熟悉的 —— greater_than_avg 函数计算出大于平均值的那个元素的索引值,然后根据该索引再去生成一个新的数组。
但是这样的方式隐藏了一个很大的Bug —— 正如上边的代码,当调用 greater_than_avg 获取索引值后,清空了数组,但是获取到的索引值却还可以被使用。
造成这个问题的原因就是,我们计算到的索引值只是按照调用 greater_than_avg时的数组状态计算出来的,一旦计算完毕,存储索引值的变量greater_index和数据本身是完全独立的,无论数据发生什么变化都不会影响到索引值,像上边的代码那样,在使用索引值以前,数组已经被清空了,如果再按照该索引值去进行下面的逻辑就会错的离谱。本质就在于,在计算索引值和使用索引值之间,没有一个机制来确保数据本身不被改变。
可以看到,这种Bug隐秘的很深,编译期间无法发现,运行期间才会被报错。
这种情况就是切片大显身手的时候了:
fn main() {
let mut arr = vec![1.3, 4.5, 8.3, 10.5];
let greater_index = greater_than_avg(&arr); // 计算大于平均值的元素索引值
arr.clear(); // 清空数组,危险!!!
println!("{:?}", greater_index);
}
fn greater_than_avg(arr: &[f32]) -> &[f32] {
let sum: f32 = arr.iter().sum(); // 计算所有元素的总和
let avg = sum / arr.len() as f32; // 计算平均值
for (index, item) in arr.iter().enumerate() {
if item > &avg{ // 如果大于平均值
return &arr[index..]; // 返回切片
}
}
&arr[arr.len()..] // 只有一个元素,或者为空的情况
}
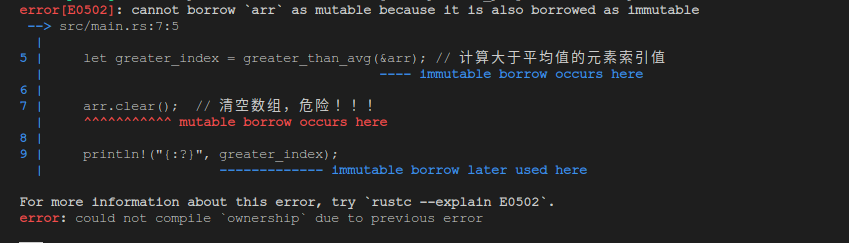
可以看到这次,我们的 greater_than_avg 函数返回的是数组的切片,而切片是数据的引用,Rust 编译器会强制我们的代码遵循上边我们深入讨论过的那条规则, 所以在调用函数 greater_than_avg 获取到切片和使用该切片之间,Rust不会允许出现独占性操作(Exclusive action), 比如清空数组。